Async Python is not faster
Async Python is slower than "sync" Python under a realistic benchmark. A bigger worry is that async frameworks go a bit wobbly under load.
Most people understand that async Python has a higher level of concurrency. It would make some sense for that to imply higher performance for common tasks like serving dynamic web sites or web APIs.
Sadly async is not go-faster-stripes for the Python interpreter.
Under realistic conditions (see below) asynchronous web frameworks are slightly worse throughput (requests/second) and much worse latency variance.
Benchmark results
I tested a wide variety of different sync and async webserver configurations:
| Webserver | Framework | Workers | P50 | P99 | Throughput |
|---|---|---|---|---|---|
| Gunicorn with meinheld | Falcon | 16 | 17 | 31 | 5589 |
| Gunicorn with meinheld | Bottle | 16 | 17 | 32 | 5780 |
| UWGGI over http | Bottle | 16 | 18 | 32 | 5497 |
| UWSGI over http | Flask | 16 | 22 | 33 | 4431 |
| Gunicorn with meinheld | Flask | 16 | 21 | 35 | 4510 |
| UWSGI over 'uwsgi' | Bottle | 16 | 18 | 36 | 5281 |
| UWSGI over http | Falcon | 16 | 18 | 37 | 5415 |
| Gunicorn | Flask | 14 | 28 | 42 | 3473 |
| Uvicorn | Starlette | 5 | 16 | 75 | 4952 |
| AIOHTTP | AIOHTTP | 5 | 19 | 76 | 4501 |
| Uvicorn | Sanic | 5 | 17 | 85 | 4687 |
| Gunicorn with gevent | Flask | 12 | 24 | 136 | 3077 |
| Daphne | Starlette | 5 | 20 | 364 | 2678 |
50th and 99th percentile response times are in milliseconds, throughput is in requests per second. The table is ordered by P99, which I think is perhaps the most important real world statistic.
Note that:
- The best performers are sync frameworks
- but Flask has lower throughput than others
- The worst performers are all async frameworks
- Async frameworks have far worse latency variation
- Uvloop-based options do better than the builtin asyncio loop
- so if you have no option but to use asyncio, use uvloop
Are these benchmarks really representative?
I think so. I tried to make them as realistic as possible. Here's the architecture I used:

I've tried to model a real world deployment as best I can. There is a reverse proxy, the python code (ie: the variable), and a database. I've also included an external database connection pooler as I think that is a pretty common feature of real deployments of web applications (at least, it is for postgresql).
The application in question queries a row by random key and returns the value as JSON. Full source code is available on github.
Why the worker count varies
The rule I used for deciding on what the optimal number of worker processes was is simple: for each framework I started at a single worker and increased the worker count successively until performance got worse.
The optimal number of workers varies between async and sync frameworks and the reasons are straightforward. Async frameworks, due to their IO concurrency, are able to saturate a single CPU with a single worker process.
The same is not true of sync workers: when they do IO they will block until the IO is finished. Consequently they need to have enough workers to ensure that all CPU cores are always in full use when under load.
For more information on this, see the gunicorn documentation:
Generally we recommend (2 x $num_cores) + 1 as the number of workers to start off with. While not overly scientific, the formula is based on the assumption that for a given core, one worker will be reading or writing from the socket while the other worker is processing a request.
Machine spec
I ran the benchmark on Hetzner's CX31 machine type, which is basically a 4 "vCPU"/8 GB RAM machine. It was run under Ubuntu 20.04. I ran the load generator on another (smaller) VM.
Why does async do worse?
Throughput
On throughput (ie: requests/second) the primary factor is not async vs sync but how much Python code has been replaced with native code. Simply put, the more performance sensitive Python code you can replace the better you will do. This is Python performance tactic with a long history (see also: numpy).
Meinheld and UWSGI (~5.3k requests/sec each) are large bodies of C code. Standard Gunicorn (~3.4k requests/sec) is pure Python.
Uvicorn+Starlette (~4.9k requests/sec) replaces much more Python code than AIOHTTP's default server (~4.5k requests/sec) (though AIOHTTP was also installed with its optional "speedups").
Latency
On latency the problem is deeper. Under load, async does badly and latency starts to spike out to a much greater extent than under a traditional, sync, deployment.
Why is this? In async Python, the multi-threading is co-operative, which
simply means that threads are not interrupted by a central governor (such as
the kernel) but instead have to voluntarily yield their execution time to
others. In asyncio, the execution is yielded upon three language keywords:
await, async for and async with.
This means that execution time is not distributed "fairly" and one thread can inadvertently starve another of CPU time while it is working. This is why latency is more erratic.
In contrast, traditional sync Python webservers like UWSGI use the pre-emptive multi-processing of the kernel scheduler, which works to ensure fairness by periodically swapping processes out from execution. This means that time is divided more fairly and that latency variance is lower.
Why do other benchmarks show different results?
The majority of other benchmarks (particularly those from async framework authors!) simply do not configure sync frameworks with enough workers. This means that those sync frameworks are effectively prevented from accessing most of the CPU time that is really available.
Here is a sample benchmark from the Vibora project. (I didn't test this framework because it's one of the less popular ones.)
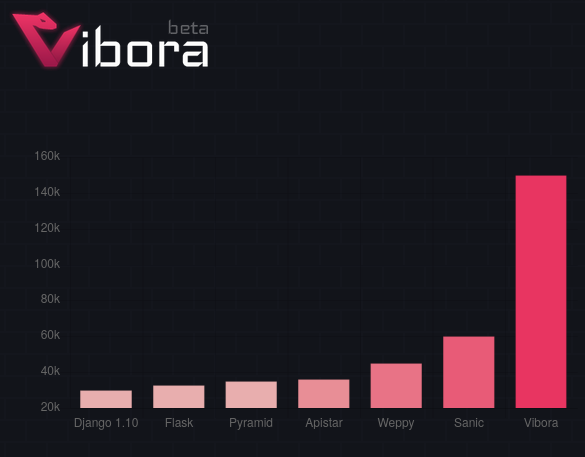
Vibora claims 500% higher throughput than Flask. However when I reviewed their benchmark code I found that they are misconfiguring Flask to use one worker per CPU. When I correct that, I get the following numbers:
| Webserver | Throughput |
|---|---|
| Flask | 11925 req/s |
| Vibora | 14148 req/s |
The throughput benefit of using Vibora over Flask is really just 18%. Flask is one of the lower throughput sync frameworks I tested so I expect that a better sync setup would be much faster than Vibora, despite the impressive looking graph.
Another problem is that many benchmarks de-prioritise latency results in favour of throughput results (Vibora's doesn't even mention it for example). However, while throughput can be improved by adding machines, latency under load doesn't get better when you do that.
Increased throughput is really only useful while latency is within an acceptable range.
Further reasoning, supposition and anecdata
Although my benchmark is fairly realistic in terms of the things involved it's still much more homogenous than a real life workload - all requests do a database query and they all do the same thing with that query. Real applications typically have much more inherent variation: there will be some slow operations, some fast ones, some that do lots of IO and some that use lots of CPU. It seems reasonable to assume (and it's true in my experience) that latency variance is actually much higher in a real application.
My hunch is that async applications' performance will be even more problematic in this case. Publicly available anecdotes are consistent with this idea:
Dan McKinley wrote about his experiences operating a Twisted-based system at Etsy. It seems that that system suffered from chronic latency variance:
[The Twisted consultants] said that although Twisted was good at overall throughput, outlying requests could experience severe latency. Which was a problem for [Etsy's system], because the way the PHP frontend used it was hundreds/thousands of times per web request.
Mike Bayer, the SQLAlchemy author, wrote Asynchronous Python and Databases several years ago in which he considers async from a slightly different perspective. He also benchmarks, and finds asyncio less efficient.
"Rachel by the Bay" wrote an article called "We have to talk about this Python, Gunicorn, Gevent thing" in which she describes operations chaos arising from a gevent-based configuration. I've also had troubles (though not performance-related) with gevent in production.
The other thing I should mention is that in the course of setting up these benchmarks every single async implementation managed to fall over in an annoying way.
Uvicorn had its parent process terminate without terminating any of its children which meant that I then had to go pid hunting for the children who were still holding onto port 8001. At one point AIOHTTP raised an internal critical error to do with file descriptors but did not exit (and so would not be restarted by any process supervisor - a cardinal sin!). Daphne also ran into trouble locally but I forget exactly how.
All of these errors were transient and easily resolved with SIGKILL. However the fact remains that I wouldn't want to be responsible for code based on these libraries in a production context. By contrast I didn't have any problems with Gunicorn or UWSGI - except that I really dislike that UWSGI doesn't exit if your app hasn't loaded correctly.
In conclusion
My recommendation: for performance purposes, just use normal, synchronous Python but use native code for as much as possible. For webservers, it's worth considering frameworks other than Flask if throughput is paramount but even Flask under UWSGI has latency characteristics as good as the best.
Thanks to my friend Tudor Munteanu for double checking my numbers!
Contact/etc
See also
Flask's original author has posted a couple of times about his concerns regarding asyncio, first posting "I don't understand Python's Asyncio" which actually gives a pretty good explanation of the technology and recently with "I'm not feeling the async pressure" in which he says:
async/await is great but it encourages writing stuff that will behave catastrophically when overloaded
What color is your function? explains some of the reasons why it is more painful to have a language with sync and async at the same time.
Function colouring is a big problem in Python and the community is now sadly bifurcated into people writing sync code and people writing async code - they can't share the same libraries. Worse yet, some async libraries are also incompatible with other async libraries so the async Python community is even further divided.
Chris Wellons wrote an article recently which also touches on latency issues and some footguns in the asyncio standard library. This is the kind of problem that makes async programs much harder to get right unfortunately.
Nathaniel J. Smith has a series of brill articles on async that I recommend to anyone trying to get to grips with it:
- Notes on structured concurrency
- Some thoughts on asynchronous API design in a post-async/await world
- Control-C handling in Python and Trio
- Timeouts and cancellation for humans
He contends that the asyncio library is misconceived. My worry is that if the big brains who debate PEPs can't get it right, what hope is there for mere mortals like myself?